Caso Técnico 03
Por qué un NAT Gateway procesó de golpe ~10 TB/día
Una investigación de costos cloud que terminó en un insight de networking: privado no significa interno.
- AWS
- FinOps
- Kubernetes
- Loki
- Networking
Resumen
Un NAT Gateway empezó a procesar un volumen inesperado de tráfico. En una ventana corta, el volumen llegó aproximadamente a 10 TB/día, generando un evento de costo que parecía problema de aplicación o workload.
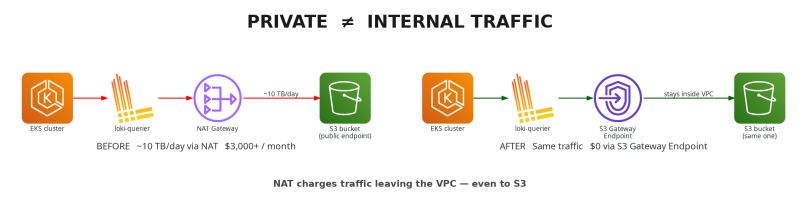
La causa raíz era distinta: Loki estaba leyendo logs almacenados en S3, pero como la VPC no tenía S3 Gateway Endpoint, ese tráfico pasaba por el NAT Gateway.
La lección clave: privado no significa automáticamente interno.
Contexto
El cluster Kubernetes usaba Loki como parte del stack de observabilidad. Loki guardaba logs en S3. El bucket era privado, el acceso estaba restringido y la aplicación funcionaba correctamente.
Pero el routing es otro problema. Sin el endpoint correcto de VPC, las subnets privadas siguen usando el NAT Gateway para llegar a S3.
Problema Visible
La señal visible era costo: los bytes procesados por NAT Gateway subieron a un nivel que no coincidía con el comportamiento normal esperado de la aplicación.
Hipótesis 01
Query productiva. Un workload podía estar trayendo un dataset grande de forma repetida.
Hipótesis 02
Cronjob o batch. Procesos programados podían haber generado tráfico en una ventana específica.
Hipótesis 03
Integración externa. Algún servicio podía haber cambiado comportamiento y movido datos por NAT.
Timeline de Investigación
- Paso 1: Confirmé bytes procesados por NAT Gateway en CloudWatch y acoté la ventana anormal.
- Paso 2: Comparé el pico de NAT con métricas de red por pod en Prometheus.
- Paso 3: Aislé tráfico de Loki querier como el workload que coincidía con el patrón del pico.
- Paso 4: Revisé la ruta de destino y encontré acceso a S3 pasando por NAT en vez de Gateway Endpoint.
Correlación de Métricas
CloudWatch mostraba el volumen total del NAT, pero no qué pod lo causaba. Prometheus mostraba bytes por pod, pero no si ese tráfico salía por NAT. El paso útil fue cruzar ambas vistas por ventana temporal.
Cuando los bytes procesados por NAT y el tráfico de pods de Loki quedaron alineados, la investigación dejó de ser sobre aplicación y pasó a ser sobre routing.
Causa Raíz
Loki estaba configurado para usar S3 como object store. La configuración era válida. Lo caro no era Loki en sí mismo, sino la ruta de red desde el cluster hacia S3.
Como la VPC no tenía S3 Gateway Endpoint, los pedidos desde subnets privadas llegaban a S3 a través del NAT Gateway. AWS cobra procesamiento de NAT por GB, así que una consulta pesada de logs se convirtió en un evento de costo cloud.
Resolución
La solución fue agregar un S3 Gateway Endpoint a las route tables usadas por las subnets privadas. Loki no necesitó cambios de aplicación. Cambió la ruta; el workload siguió funcionando.
Impacto Operativo
Ruta de costo eliminada
El tráfico S3 de alto volumen dejó de ser procesado por el NAT Gateway.
Sin reescribir aplicación
El workload siguió funcionando igual. Lo que cambió fue la ruta de infraestructura.
Mejor patrón de investigación
El equipo ganó un método para conectar señales de costo cloud con métricas a nivel workload.
Regla de plataforma más clara
Los servicios privados en AWS igual necesitan rutas privadas explícitas.
Patrón FinOps Reutilizable
Esto quedó como patrón reutilizable para anomalías de costo cloud: partir de la señal de billing, identificar el componente de infraestructura, correlacionar con métricas de workloads y validar route tables o endpoints involucrados.
- CloudWatch para bytes procesados por NAT.
- Prometheus para tráfico por pod.
- Route tables y VPC endpoints para validar el camino.
- Servicios de alto volumen conocidos: logs, backups, exports y cargas analíticas.
Trade-offs
La solución fue simple, pero la investigación no. El trade-off principal es disciplina operativa: VPC endpoints y route tables tienen que formar parte del diseño de plataforma, no aparecer recién cuando el costo explota.
Resultado
- El tráfico de NAT Gateway volvió a valores normales.
- Se eliminó la ruta cara sin cambiar el comportamiento de Loki.
- El método de investigación quedó como patrón reutilizable para futuros análisis FinOps.
- Quedó una regla clara: buckets privados igual necesitan rutas privadas.
Qué Mejoraría Después
El siguiente paso no es solo prevenir este problema puntual. Es construir un runbook repetible de investigación de costos cloud: métricas de NAT, endpoints de VPC, tráfico por pod, route tables y servicios de alto volumen conocidos.