Caso Técnico 02
De cuellos de botella en Power BI a una arquitectura warehouse-first
Cómo una capa de BI sobrecargada pasó a una arquitectura warehouse-first moviendo el ownership de transformación fuera de Power BI.
- Warehouse-first
- PostgreSQL
- Power BI
- ETL
- Python
Resumen
El problema visible era Power BI: refreshes lentos, alto consumo de memoria y reportes cada vez más difíciles de mantener. Pero Power BI no era la causa raíz.
El problema real era ownership de transformación. La capa de BI había absorbido joins, filtros, reglas de negocio y responsabilidades de modelado que debían vivir en una capa analítica controlada.
Idea central: el dashboard era el lugar donde aparecía el problema, no el lugar donde había que resolver el sistema.
Contexto
La capa de reporting consumía datos directamente desde varias fuentes operacionales: una base documental con transacciones de negocio y una base relacional con estados de workflow. Power BI conectaba esas fuentes, unía registros, filtraba históricos y calculaba métricas dentro de la misma capa de reporte.
La arquitectura había crecido de forma orgánica. Funcionaba con bajo volumen, pero con el tiempo la herramienta de visualización se convirtió en el lugar donde se armaba gran parte del sistema analítico.
Problema Visible
El refresh del dashboard dependía de un gateway que tenía que traer mucha información histórica, unir registros de motores distintos y aplicar cálculos de negocio dentro de Power Query.
- Las transformaciones de Power Query consumían demasiada memoria.
- Algunas transformaciones no podían empujarse a las bases origen.
- La lógica de negocio estaba duplicada en distintos reportes.
- Las bases operacionales estaban siendo usadas como fuentes analíticas.
El síntoma parecía performance de reportes. El problema de sistema era más profundo: una herramienta de BI estaba cargando demasiado ownership analítico.
Hipótesis Iniciales
Hipótesis 01
Límite del gateway. El gateway podía ser el cuello de botella por mover demasiada data histórica en un solo camino.
Hipótesis 02
Carga de Power Query. Transformaciones que no podían empujarse al origen estaban consumiendo memoria durante el refresh.
Hipótesis 03
Desajuste de diseño. Bases operacionales estaban siendo usadas como fuentes analíticas sin un modelo intermedio.
Cambio de Arquitectura
Antes
Power BI como capa de transformación. Las fuentes se consultaban directo, las reglas vivían en archivos de reporte y los refreshes dependían mucho del gateway.
Después
Flujo warehouse-first. Python ETL cargó estructuras analíticas curadas en PostgreSQL y Power BI consumió un modelo más claro.
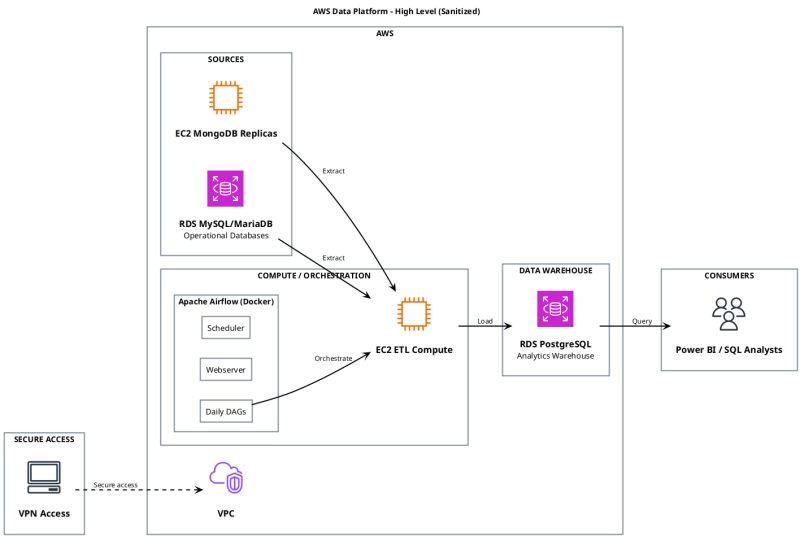
Investigación
Seguí el flujo desde los sistemas origen hasta el reporte final en vez de ajustar solo el dashboard visible. La pregunta útil no era “cómo hacemos más rápido este reporte”, sino “por qué este reporte es responsable de tanto trabajo”.
- Identifiqué transformaciones dentro de Power Query que pertenecían upstream.
- Separé filtros de extracción de filtros de presentación.
- Busqué reglas de negocio duplicadas en distintos reportes.
- Mapeé qué partes del flujo estaban en archivos BI, scripts, bases de datos y personas.
Causa Raíz
La causa raíz no era una consulta lenta ni una visualización mal hecha. Era drift arquitectónico. Power BI se había convertido en una mezcla de herramienta visual, motor de transformación y contenedor de lógica de negocio.
Eso afectaba performance, pero también ownership. Cuando la lógica vive dentro de archivos de reporte, se vuelve más difícil de testear, reutilizar, revisar y operar.
Decisiones Clave
La primera mejora fue mover los filtros de fecha más temprano en el pipeline. En lugar de cargar todo y filtrar después, el ETL extraía solo la ventana relevante antes de unir fuentes.
La segunda mejora fue usar cargas idempotentes con UPSERT. Si una corrida fallaba y se reintentaba, el warehouse convergía al mismo estado final en lugar de generar duplicados.
La tercera mejora fue modelar tablas analíticas explícitas en vez de exponer estructuras operacionales crudas a Power BI.
Qué Cambió Operativamente
Menos lógica duplicada
Las reglas de negocio pasaron a una capa analítica central en vez de copiarse entre archivos de reporte.
Menos dependencia del gateway
El camino de refresh quedó más liviano porque Power BI consumió tablas curadas en vez de traer y transformar data operacional cruda.
Más reutilización
Los nuevos reportes pudieron usar el mismo modelo de warehouse sin reconstruir joins y métricas.
Ownership más claro
La plataforma quedó a cargo de la lógica de transformación; Power BI volvió a enfocarse en reporting y consumo.
Trade-offs
Este enfoque agregó una capa nueva para mantener: pipelines, migraciones, monitoreo y documentación. Pero eliminó una complejidad peor: lógica de negocio escondida dentro de archivos de reporte difíciles de testear, versionar y reutilizar.
Resultado
- Power BI quedó más liviano y fácil de mantener.
- La lógica de negocio se movió a una capa central de warehouse.
- Los nuevos reportes pudieron reutilizar el mismo modelo curado.
- La arquitectura se volvió más fácil de razonar y operar.
Lecciones Aprendidas
Un dashboard puede ser la parte más visible del sistema, pero eso no significa que deba ser dueño del sistema. El reporting confiable suele empezar antes: en el modelado, el ownership de transformación, los límites operativos y el camino que sigue el dato antes de que alguien abra Power BI.